Use case: Amino Acid Metabolites of Dietary Salt Effects on Blood Pressure in Human Urine
Pol Castellano-Escuder
Duke Universitypolcaes@gmail.com
6 May 2024
Source:vignettes/MW_ST000629_enrichment.Rmd
MW_ST000629_enrichment.RmdCompiled date: 2024-05-06
Last edited: 2024-02-12
License: GPL-3
Installation
Run the following code to install the Bioconductor version of the package.
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install("fobitools")Load packages
We will also need some additional CRAN and Bioconductor packages for performing tasks such as statistical analysis.
Download the data from Metabolomics Workbench
The Metabolomics Workbench, available at www.metabolomicsworkbench.org, is a public repository for metabolomics metadata and experimental data spanning various species and experimental platforms, metabolite standards, metabolite structures, protocols, tutorials, and training material and other educational resources. It provides a computational platform to integrate, analyze, track, deposit and disseminate large volumes of heterogeneous data from a wide variety of metabolomics studies including mass spectrometry (MS) and nuclear magnetic resonance spectrometry (NMR) data spanning over 20 different species covering all the major taxonomic categories including humans and other mammals, plants, insects, invertebrates and microorganisms (Sud et al. 2016).
The metabolomicsWorkbenchR Bioconductor package allows
us to obtain data from the Metabolomics Workbench repository. In this
vignette we will use the sample data set ST000629.
Sumary of the study (ST000629)
The objective of the study is to identify changes of urinary metabolite profiles associated with different responses to blood pressure to salt. Subjects are derived from The Dietary approaches to stop hypertension (DASH) diet, Sodium Intake and Blood Pressure Trial (Sacks FM et al PMID: 11136953,N Engl J Med. 2001).We choose two groups subjects who meet the following conditions (the two groups are separately named A and B). We chose subjects on the Control diet. These subjects meet the blood pressure criteria described below:Group A subjects conditions: 1) On Control diet. 2) Normotensive subjects: systolic blood pressure from the low sodium visit is less than 140 and the diastolic blood pressure from low sodium visit is less than 90; 3) For group A: Either the systolic blood pressure from the high sodium visit was greater than 10 mmHg higher than the systolic blood pressure from the low sodium visit, or the diastolic blood pressure from the high sodium visit was greater than 10 mmHg higher than the diastolic blood pressure from the low sodium visit; 3) For group B: The systolic blood pressure from the high sodium visit is within 5 mmHg (i.e. +/- 5) from the systolic blood pressure from the low sodium visit, and the diastolic blood pressure from the high sodium visit is within 5 mmHg from the diastolic blood pressure from the low sodium visit. Use gas chromatography/mass spectrometry (GC/MS) analysis, and liquid chromatography/mass spectrometry (LC/MS) analysis to find the differences of metabolic profiles between the high sodium level and the low sodium level, and compare the metabolic profiles of A with the metabolic profiles of B at the low and high sodium level.
Download data
This study includes compounds analyzed via MS analysis and positive ion mode (AN000961). Let’s download it!
data <- do_query(
context = "study",
input_item = "analysis_id",
input_value = "AN000961",
output_item = "SummarizedExperiment")Prepare features and metadata
Now we have to prepare the metadata and features in order to proceed with the statistical analysis. In this step we assign to each metabolite its chemical name provided in Metabolomics Workbench.
## features
features <- assay(data)
rownames(features) <- rowData(data)$metabolite
## metadata
pdata <- colData(data) %>%
as.data.frame() %>%
tibble::rownames_to_column("ID") %>%
relocate(grouping, .before = Sodium.level) %>%
mutate(grouping = case_when(grouping == "A(salt sensitive)" ~ "A",
grouping == "B(salt insensitive)" ~ "B"))Statistical analysis with POMA
POMA provides a structured, reproducible and easy-to-use
workflow for the visualization, preprocessing, exploration, and
statistical analysis of metabolomics and proteomics data. The main aim
of this package is to enable a flexible data cleaning and statistical
analysis processes in one comprehensible and user-friendly R package.
POMA uses the standardized
SummarizedExperiment data structures, to achieve the
maximum flexibility and reproducibility and makes POMA
compatible with other Bioconductor packages (Castellano-Escuder, Andrés-Lacueva, and Sánchez-Pla
2021).
Create a SummarizedExperiment object
First, we create a SummarizedExperiment object that
integrates both metadata and features in the same data structure.
data_sumexp <- PomaCreateObject(metadata = pdata, features = t(features))Preprocessing
Second, we perform the preprocessing step. This step includes the missing value imputation using the \(k\)-NN algorithm and log Pareto normalization (transformation and scaling). Once these steps are completed, we can proceed to the statistical analysis of these data.
data_preprocessed <- data_sumexp %>%
PomaImpute() %>%
PomaNorm()Limma model
We use a limma model (Ritchie et al. 2015) to identify those most significant metabolites between the “A(salt sensitive)” and “B(salt insensitive)” groups.
limma_res <- data_preprocessed %>%
PomaLimma(contrast = "A-B", adjust = "fdr") %>%
dplyr::rename(ID = feature)
# show the first 10 features
limma_res %>%
dplyr::slice(1L:10L) %>%
kbl(row.names = FALSE, booktabs = TRUE) %>%
kable_styling(latex_options = c("striped"))| ID | logFC | AveExpr | t | pvalue | adj_pvalue | B |
|---|---|---|---|---|---|---|
| METHIONINE | 0.6455437 | 0 | 4.548993 | 0.0000429 | 0.0008338 | 1.9296634 |
| LEUCINE | 0.7526845 | 0 | 4.496607 | 0.0000507 | 0.0008338 | 1.7702115 |
| ISOLEUCINE | 0.6131954 | 0 | 4.438771 | 0.0000610 | 0.0008338 | 1.5949155 |
| SERINE | 0.8002490 | 0 | 4.039486 | 0.0002142 | 0.0021955 | 0.4087225 |
| ASPARAGINE | 0.5681480 | 0 | 3.676917 | 0.0006451 | 0.0052895 | -0.6250585 |
| VALINE | 0.5223869 | 0 | 3.480890 | 0.0011498 | 0.0078573 | -1.1633626 |
| THREONINE | 0.4532041 | 0 | 2.954335 | 0.0050404 | 0.0295221 | -2.5231755 |
| PHENYLALANINE | 0.3829642 | 0 | 2.817394 | 0.0072542 | 0.0371778 | -2.8533955 |
| GLUTAMINE | 0.3536959 | 0 | 2.464353 | 0.0177506 | 0.0808637 | -3.6535500 |
| HOMOCYSTINE | 0.2830360 | 0 | 2.282725 | 0.0273923 | 0.1123085 | -4.0340283 |
Convert metabolite names to KEGG identifiers with
MetaboAnalyst web server
In many metabolomics studies, the reproducibility of analyses is
severely affected by the poor interoperability of metabolite names and
their identifiers. For this reason it is important to develop tools that
facilitate the process of converting one type of identifier to another.
In order to use the fobitools package, we need some generic
identifier (such as PubChem, KEGG or HMDB) that allows us to obtain the
corresponding FOBI identifier for each metabolite. However, unlike
vignette “Use case ST000291”, the Metabolomics Workbench
repository does not provide us with this information for the metabolites
quantified in study ST000629.
In those cases where we do not have other common identifiers, the authors recommend using the powerful conversion tool provided by MetaboAnalyst. This tool will allow us to move from the metabolite names to other generic identifiers such as KEGG or HMDB, which will later allow us to obtain the FOBI identifier of these metabolites.
In order to use the MetaboAnalyst ID conversion tool, we can copy the
result of the following cat() command and paste it directly
into MetaboAnalyst (Figure @ref(fig:MAconvertID)).
cat(limma_res$ID, sep = "\n")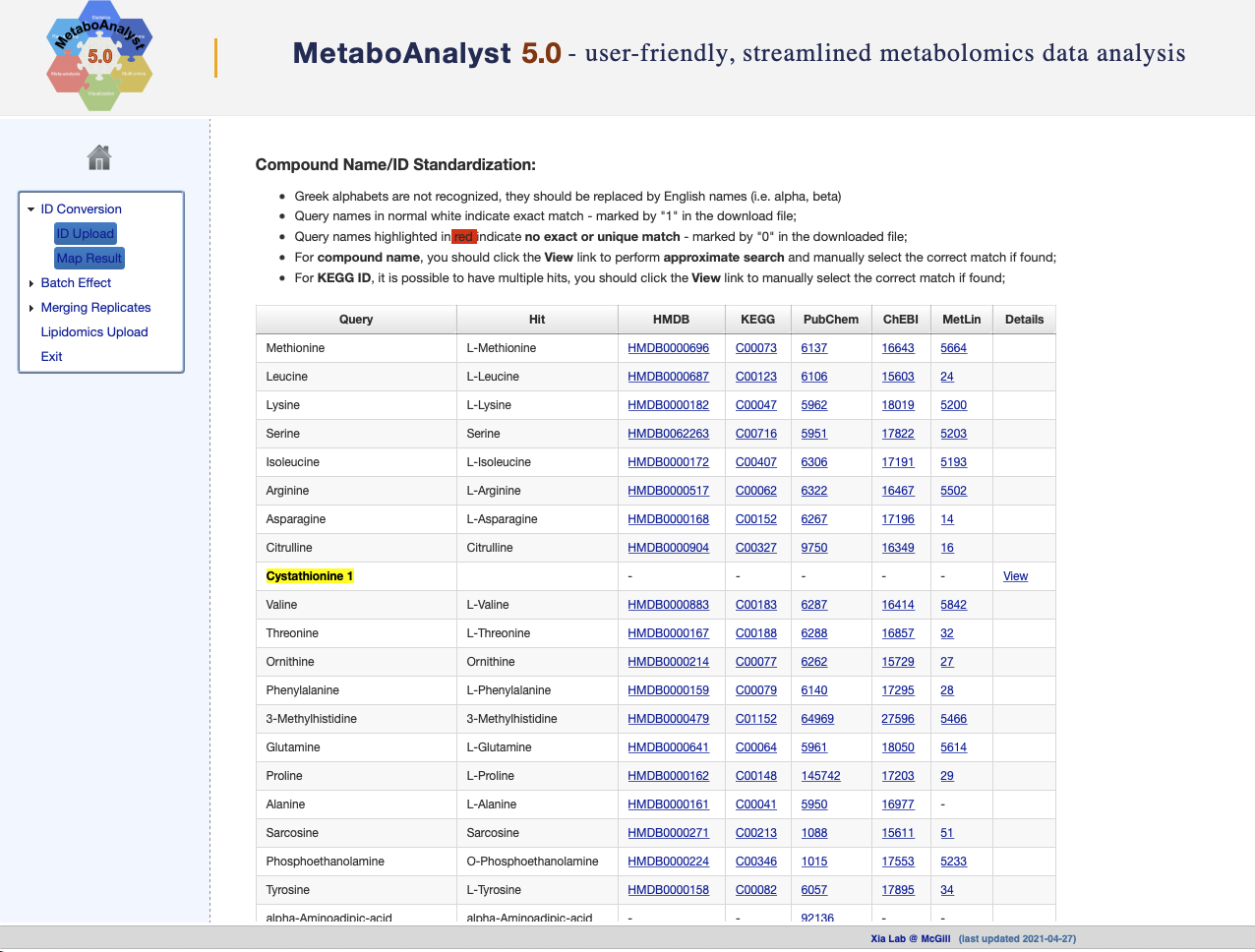
Metabolite names conversion using MetaboAnalyst.
Then, we can access to the MetaboAnalyst temporary page that is hosting our results (where the following “XXXXXXX” will be your guest URL).
ST000629_MetaboAnalyst_MapNames <- readr::read_delim("https://www.metaboanalyst.ca/MetaboAnalyst/resources/users/XXXXXXX/name_map.csv", delim = ",")Convert KEGG IDs to FOBI IDs
Once we have the results of the statistical analysis and generic
identifiers recognized in the FOBI ontology (Castellano-Escuder et al.
2020), we can proceed to perform one of the main functions
provided by the fobitools package, the ID conversion. With
the fobitools::id_convert() command, users can convert
different IDs between FOBI, HMDB, KEGG, PubChem, InChIKey, InChICode,
ChemSpider, and chemical names. We will then obtain the FOBI IDs from
the KEGG IDs (obtained in the previous section via MetaboAnalyst web
server) and add them as a new column to the results of the limma
model.
annotated_limma <- ST000629_MetaboAnalyst_MapNames %>%
dplyr::rename(ID = Query) %>%
dplyr::mutate(ID = tolower(ID)) %>%
dplyr::right_join(limma_res %>%
dplyr::mutate(ID = tolower(ID)),
by = "ID")
limma_FOBI_names <- annotated_limma %>%
dplyr::pull("KEGG") %>%
fobitools::id_convert(to = "FOBI")
# show the ID conversion results
limma_FOBI_names %>%
head() %>%
kbl(row.names = FALSE, booktabs = TRUE) %>%
kable_styling(latex_options = c("striped"))| FOBI | KEGG |
|---|---|
| FOBI:030687 | C00386 |
| FOBI:030709 | C00245 |
| FOBI:030701 | C00078 |
| FOBI:030692 | C00079 |
| FOBI:030697 | C00082 |
| FOBI:030688 | C01262 |
Enrichment analysis
Enrichment analysis denotes any method that benefits from biological pathway or network information to gain insight into a biological system (Creixell et al. 2015). In other words, these type of analyses integrate the existing biological knowledge (from different biological sources such as databases and ontologies) and the statistical results of omics studies, obtaining a deeper understanding of biological systems.
In most metabolomics studies, the output of statistical analysis is usually a list of features selected as statistically significant or statistically relevant according to a pre-defined statistical criteria. Enrichment analysis methods use these selected features to explore associated biologically relevant pathways, diseases, etc., depending on the nature of the input feature list (genes, metabolites, etc.) and the source used to extract the biological knowledge (GO, KEGG, FOBI, etc.).
Here, we present a tool that uses the FOBI information to perform different types of enrichment analyses. Therefore, the presented methods allow researchers to move from lists of metabolites to chemical classes and food groups associated with those lists, and consequently, to the study design.
Currently, the most popular used approaches for enrichment analysis are the over representation analysis (ORA) and the gene set enrichment analysis (GSEA), with its variants for other fields such as the metabolite set enrichment analysis (MSEA) (Xia and Wishart 2010).
Over representation analysis (ORA)
ORA is one of the most used methods to perform enrichment analysis in metabolomics studies due to its simplicity and easy understanding. This method statistically evaluates the fraction of metabolites in a particular pathway found among the set of metabolites statistically selected. Thus, ORA is used to test if certain groups of metabolites are represented more than expected by chance given a feature list.
However, ORA has a number of limitations. The most important one is the need of using a certain threshold or criteria to select the feature list. This means that metabolites do not meet the selection criteria must be discarded. The second big limitation of ORA is that this method assumes independence of sets and features. In ORA, is assumed that each feature is independent of the other features and each set is independent of the other sets.
Here, we perform an ORA with the fobitools package,
where we will use as a universe all the metabolites of the study present
in FOBI and as a list those metabolites with a raw p-value < 0.05 in
the limma results table.
metaboliteList <- limma_FOBI_names$FOBI[limma_FOBI_names$pvalue < 0.05]
metaboliteUniverse <- limma_FOBI_names$FOBI
fobitools::ora(metaboliteList = metaboliteList,
metaboliteUniverse = metaboliteUniverse,
pvalCutoff = 1) %>%
kbl(row.names = FALSE, booktabs = TRUE) %>%
kable_styling(latex_options = c("striped"))| className | classSize | overlap | pval | padj | overlapMetabolites |
|---|---|---|---|---|---|
| dairy food product | 3 | 1 | 0.5 | 0.7142857 | FOBI:030692 |
| egg food product | 3 | 1 | 0.5 | 0.7142857 | FOBI:030692 |
| legume food product | 3 | 1 | 0.5 | 0.7142857 | FOBI:030692 |
| meat food product | 3 | 1 | 0.5 | 0.7142857 | FOBI:030692 |
| nut (whole or part) | 3 | 1 | 0.5 | 0.7142857 | FOBI:030692 |
| soybean (whole) | 3 | 1 | 0.5 | 0.7142857 | FOBI:030692 |
| Whole grain cereal products | 3 | 1 | 0.5 | 0.7142857 | FOBI:030692 |
| fish | 1 | 0 | 1.0 | 1.0000000 | |
| Lean meat | 3 | 0 | 1.0 | 1.0000000 | |
| Red meat | 2 | 0 | 1.0 | 1.0000000 |
MSEA
Gene Set Enrichment Analysis (GSEA) methodology was proposed for the first time in 2005, with the aim of improving the interpretation of gene expression data. The main purpose of GSEA is to determine whether members of a gene set \(S\) tend to occur toward the top (or bottom) of the gene list \(L\), in which case the gene set is correlated with the phenotypic class distinction (Subramanian et al. 2005).
This type of analysis basically consists of three key steps (Subramanian et al. 2005):
The first step consists on the calculation of an enrichment score (\(ES\)). This value indicates the degree to which a set \(S\) is overrepresented at the extremes (top or bottom) of the entire ranked gene list \(L\). The \(ES\) is calculated by walking down the list \(L\), increasing a running-sum statistic when a gene is found in \(S\) and decreasing it when a gene is not found in \(S\). The magnitude of the increment depends on the correlation of the gene with the phenotype. The \(ES\) is the maximum deviation from zero encountered in the random walk.
The second step is the estimation of significance level of \(ES\). The statistical significance (nominal p-value) of the \(ES\) is estimated by using an empirical phenotype-based permutation test that preserves the complex correlation structure of the gene expression data. The phenotype labels (\(L\)) are permuted and the \(ES\) of the \(S\) is recomputed for the permuted data, which generates a null distribution for the \(ES\). The empirical, nominal p-value of the observed \(ES\) is then calculated relative to this null distribution. The permutation of class labels (groups) preserves gene-gene correlations and, thus, provides a more biologically reasonable assessment of significance than would be obtained by permuting genes.
Finally, the third step consist on the adjustment for multiple hypothesis testing. When an entire database of gene sets is evaluated, the estimated significance level is adjusted for multiple hypothesis testing. First, the \(ES\) is normalized for each gene set to account for the size of the set, yielding a normalized enrichment score (NES). Then, the proportion of false positives is controlled by calculating the FDR corresponding to each NES.
In 2010, a modification of the GSEA methodology was presented for metabolomics studies. This method was called Metabolite Set Enrichment Analysis (MSEA) and its main aim was to help researchers identify and interpret patterns of human and mammalian metabolite concentration changes in a biologically meaningful context (Xia and Wishart 2010). MSEA is currently widely used in the metabolomics community and it is implemented and freely available at the known MetaboAnalyst web-based tool (Xia and Wishart 2010).
As can be seen, GSEA approach is more complex than the ORA methodology, both in terms of methodological aspects and understanding of the method.
The fobitools package provides a function to perform
MSEA using the FOBI information. This function requires a ranked list.
Here, we will use the metabolites obtained in the limma model ranked by
raw p-values.
limma_FOBI_msea <- limma_FOBI_names %>%
select(FOBI, pvalue) %>%
filter(!is.na(FOBI)) %>%
dplyr::arrange(-dplyr::desc(abs(pvalue)))
FOBI_msea <- as.vector(limma_FOBI_msea$pvalue)
names(FOBI_msea) <- limma_FOBI_msea$FOBI
msea_res <- fobitools::msea(FOBI_msea, pvalCutoff = 1)
msea_res %>%
kbl(row.names = FALSE, booktabs = TRUE) %>%
kable_styling(latex_options = c("striped"))| className | classSize | log2err | ES | NES | pval | padj | leadingEdge |
|---|---|---|---|---|---|---|---|
| Lean meat | 3 | 0.2065879 | 1.00 | 1.671813 | 0.0469530 | 0.4695305 | FOBI:030…. |
| fish | 1 | 0.0658312 | 0.80 | 1.603206 | 0.3246753 | 1.0000000 | FOBI:030688 |
| Red meat | 2 | 0.0584693 | 0.75 | 1.288853 | 0.3786214 | 1.0000000 | FOBI:030…. |
| Whole grain cereal products | 3 | 0.0000000 | 0.00 | 0.000000 | 1.0000000 | 1.0000000 | FOBI:030…. |
| dairy food product | 3 | 0.0000000 | 0.00 | 0.000000 | 1.0000000 | 1.0000000 | FOBI:030…. |
| egg food product | 3 | 0.0000000 | 0.00 | 0.000000 | 1.0000000 | 1.0000000 | FOBI:030…. |
| legume food product | 3 | 0.0000000 | 0.00 | 0.000000 | 1.0000000 | 1.0000000 | FOBI:030…. |
| meat food product | 3 | 0.0000000 | 0.00 | 0.000000 | 1.0000000 | 1.0000000 | FOBI:030…. |
| nut (whole or part) | 3 | 0.0000000 | 0.00 | 0.000000 | 1.0000000 | 1.0000000 | FOBI:030…. |
| soybean (whole) | 3 | 0.0000000 | 0.00 | 0.000000 | 1.0000000 | 1.0000000 | FOBI:030…. |
MSEA plot with ggplot2
ggplot(msea_res, aes(x = -log10(pval), y = NES, color = NES, size = classSize, label = className)) +
xlab("-log10(P-value)") +
ylab("NES (Normalized Enrichment Score)") +
geom_point() +
ggrepel::geom_label_repel(color = "black", size = 7) +
theme_bw() +
theme(legend.position = "top",
text = element_text(size = 22)) +
scale_color_viridis_c() +
scale_size(guide = "none")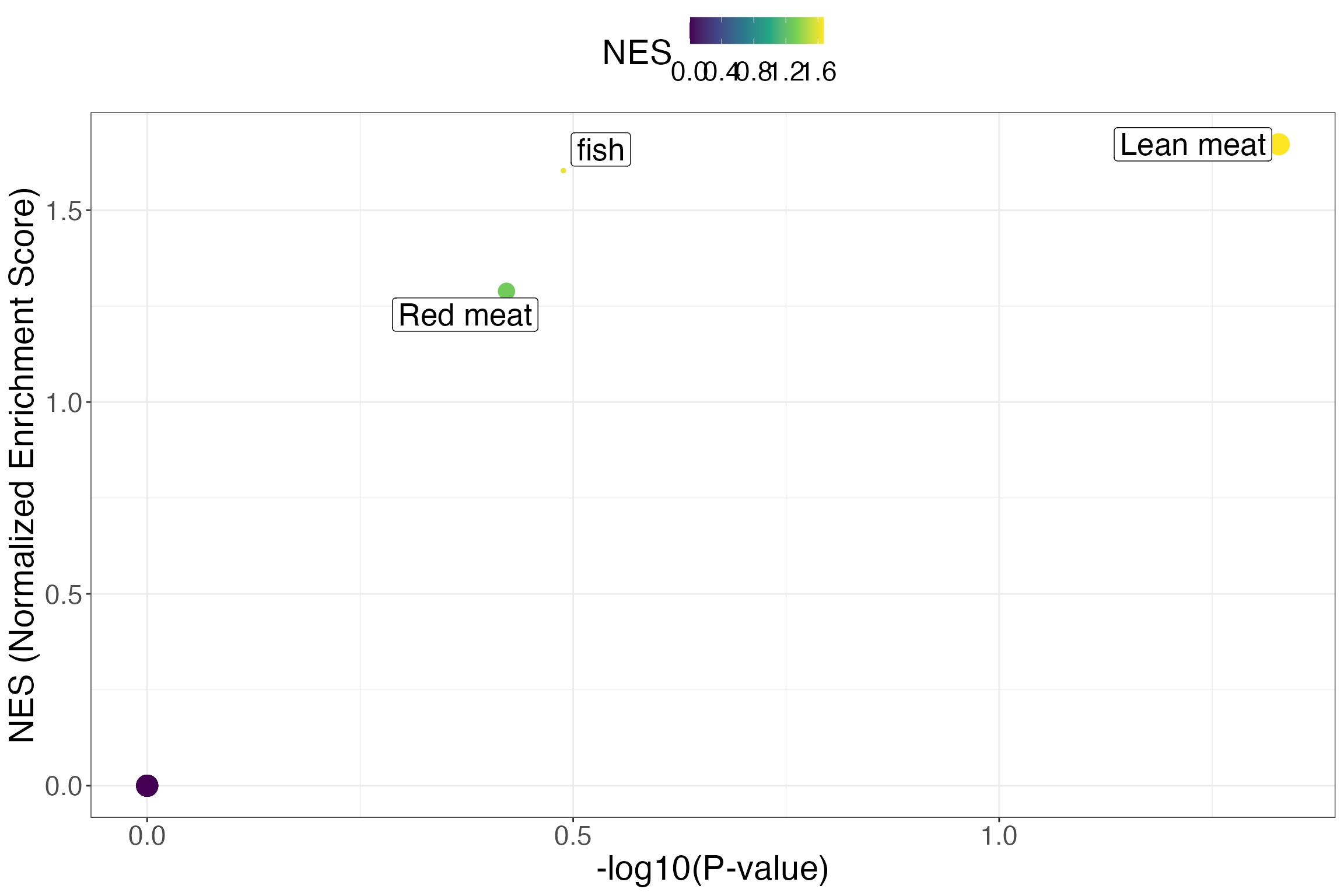
Limitations
The FOBI ontology is currently in its first release version, so it
does not yet include information on many metabolites and food
relationships. All future efforts will be directed at expanding this
ontology, leading to a significant increase in the number of metabolites
and metabolite-food relationships. The fobitools package
provides the methodology for easy use of the FOBI ontology regardless of
the amount of information it contains. Therefore, future FOBI
improvements will also have a direct impact on the
fobitools package, increasing its utility and allowing to
perform, among others, more accurate, complete and robust enrichment
analyses.
Session Information
sessionInfo()
#> R version 4.3.2 (2023-10-31)
#> Platform: aarch64-apple-darwin20 (64-bit)
#> Running under: macOS Sonoma 14.1
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/lib/libRlapack.dylib; LAPACK version 3.11.0
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> time zone: America/New_York
#> tzcode source: internal
#>
#> attached base packages:
#> [1] stats4 stats graphics grDevices utils datasets methods
#> [8] base
#>
#> other attached packages:
#> [1] SummarizedExperiment_1.32.0 Biobase_2.62.0
#> [3] GenomicRanges_1.54.1 GenomeInfoDb_1.38.5
#> [5] IRanges_2.36.0 S4Vectors_0.40.2
#> [7] BiocGenerics_0.48.1 MatrixGenerics_1.14.0
#> [9] matrixStats_1.2.0 metabolomicsWorkbenchR_1.12.0
#> [11] POMA_1.13.13 kableExtra_1.3.4
#> [13] ggrepel_0.9.5 lubridate_1.9.3
#> [15] forcats_1.0.0 stringr_1.5.1
#> [17] dplyr_1.1.4 purrr_1.0.2
#> [19] readr_2.1.4 tidyr_1.3.0
#> [21] tibble_3.2.1 ggplot2_3.4.4
#> [23] tidyverse_2.0.0 fobitools_1.11.2
#> [25] BiocStyle_2.30.0
#>
#> loaded via a namespace (and not attached):
#> [1] rstudioapi_0.15.0 jsonlite_1.8.8
#> [3] MultiAssayExperiment_1.28.0 magrittr_2.0.3
#> [5] farver_2.1.1 rmarkdown_2.25
#> [7] zlibbioc_1.48.0 fs_1.6.3
#> [9] ragg_1.2.7 vctrs_0.6.5
#> [11] memoise_2.0.1 RCurl_1.98-1.13
#> [13] janitor_2.2.0 webshot_0.5.5
#> [15] S4Arrays_1.2.0 htmltools_0.5.7
#> [17] curl_5.2.0 qdapRegex_0.7.8
#> [19] tictoc_1.2 SparseArray_1.2.3
#> [21] sass_0.4.8 parallelly_1.36.0
#> [23] bslib_0.6.1 desc_1.4.3
#> [25] impute_1.76.0 RecordLinkage_0.4-12.4
#> [27] cachem_1.0.8 igraph_1.6.0
#> [29] lifecycle_1.0.4 pkgconfig_2.0.3
#> [31] Matrix_1.6-1 R6_2.5.1
#> [33] fastmap_1.1.1 snakecase_0.11.1
#> [35] GenomeInfoDbData_1.2.11 future_1.33.1
#> [37] digest_0.6.34 colorspace_2.1-0
#> [39] textshaping_0.3.7 RSQLite_2.3.4
#> [41] labeling_0.4.3 fansi_1.0.6
#> [43] timechange_0.2.0 abind_1.4-5
#> [45] httr_1.4.7 polyclip_1.10-6
#> [47] compiler_4.3.2 proxy_0.4-27
#> [49] bit64_4.0.5 withr_2.5.2
#> [51] BiocParallel_1.36.0 viridis_0.6.4
#> [53] DBI_1.2.0 highr_0.10
#> [55] ggforce_0.4.1 MASS_7.3-60
#> [57] lava_1.7.3 DelayedArray_0.28.0
#> [59] textclean_0.9.3 tools_4.3.2
#> [61] future.apply_1.11.1 nnet_7.3-19
#> [63] glue_1.7.0 grid_4.3.2
#> [65] fgsea_1.28.0 generics_0.1.3
#> [67] gtable_0.3.4 tzdb_0.4.0
#> [69] class_7.3-22 data.table_1.14.10
#> [71] hms_1.1.3 tidygraph_1.3.0
#> [73] xml2_1.3.6 utf8_1.2.4
#> [75] XVector_0.42.0 pillar_1.9.0
#> [77] limma_3.58.1 vroom_1.6.5
#> [79] splines_4.3.2 tweenr_2.0.2
#> [81] lattice_0.22-5 survival_3.5-7
#> [83] bit_4.0.5 tidyselect_1.2.0
#> [85] knitr_1.45 gridExtra_2.3
#> [87] bookdown_0.37 svglite_2.1.3
#> [89] xfun_0.41 graphlayouts_1.0.2
#> [91] statmod_1.5.0 stringi_1.8.3
#> [93] yaml_2.3.8 evaluate_0.23
#> [95] codetools_0.2-19 evd_2.3-6.1
#> [97] ggraph_2.1.0 BiocManager_1.30.22
#> [99] cli_3.6.2 ontologyIndex_2.11
#> [101] rpart_4.1.23 xtable_1.8-4
#> [103] systemfonts_1.0.5 struct_1.14.0
#> [105] munsell_0.5.0 jquerylib_0.1.4
#> [107] Rcpp_1.0.12 globals_0.16.2
#> [109] parallel_4.3.2 pkgdown_2.0.7
#> [111] blob_1.2.4 bitops_1.0-7
#> [113] ff_4.0.12 listenv_0.9.0
#> [115] viridisLite_0.4.2 ipred_0.9-14
#> [117] scales_1.3.0 prodlim_2023.08.28
#> [119] e1071_1.7-14 crayon_1.5.2
#> [121] clisymbols_1.2.0 rlang_1.1.3
#> [123] ada_2.0-5 cowplot_1.1.2
#> [125] fastmatch_1.1-4 rvest_1.0.3